https://lookerstudio.google.com/reporting/012dfebb-c7c0-4578-9e3e-fb886eaa147f/page/NYjUE
日本のサウナのダッシュボードを公開。
色んな条件で絞込ができるので、好みのサウナがみつかります。
https://lookerstudio.google.com/reporting/012dfebb-c7c0-4578-9e3e-fb886eaa147f/page/NYjUE
日本のサウナのダッシュボードを公開。
色んな条件で絞込ができるので、好みのサウナがみつかります。
今回はデータの可視化(BI)ツールをいくつかご紹介します。すべて無料で使えるものなので、気軽にお試しすることができます。実際どのように可視化ができるのか、操作した例もあわせてご紹介していきます。
そもそもなぜデータを可視化するのか、可視化するメリットを考えてみます。
文字や数字の羅列よりも絵で示した方が人間にはわかりやすいです。例えば、Webページのアクセス数が多いのか少ないのか、増えているのか減っているのか、急激な変化か緩やかな変化か、といったデータの特徴は、可視化することによって簡単に読み取れるようになります。
その1と似た内容になりますが、可視化をすることにより、データの傾向がわかりやすくなります。先ほどのWebページのアクセス数で言うと、単純に増えているか、減っているかだけではなく、アクセスの増加率が上がっているとか、ある特定のカテゴリの記事がじわじわ伸びているなどの傾向が読み取れるようになります。
分析結果を誰かと共有する際にも可視化は役立ちます。例えば、ある店舗の売り上げを定期報告する場合、売り上げ金額の数字だけではなく、これまでのデータの推移や、商品カテゴリごとの売り上げの伸び率などを可視化して報告することにより、今後どの商品に注力するかなど、有意義な意見交換ができそうです。
以上のように、データを可視化することよってさまざまなメリットが得られます。
無料で使える可視化ツールにはどういったものがあるのでしょうか。それぞれの特徴や利点をご紹介していきます。(利点については、あくまでも主観になりますのでご注意ください)
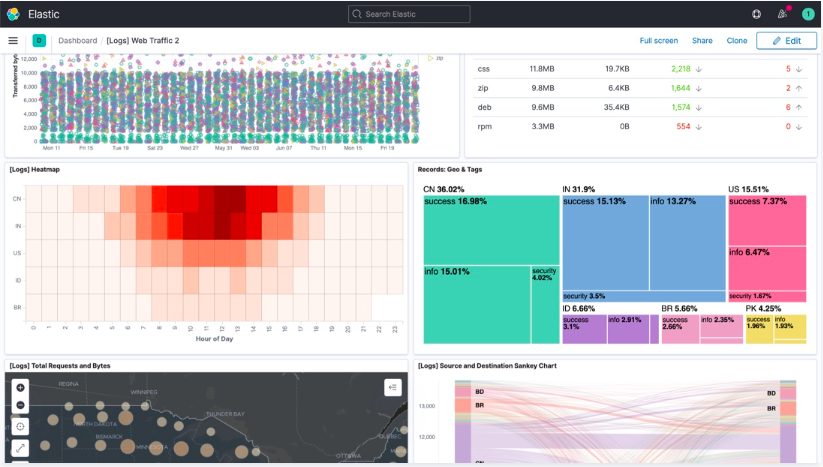
クラウド版を利用 or パッケージをダウンロードしてインストール
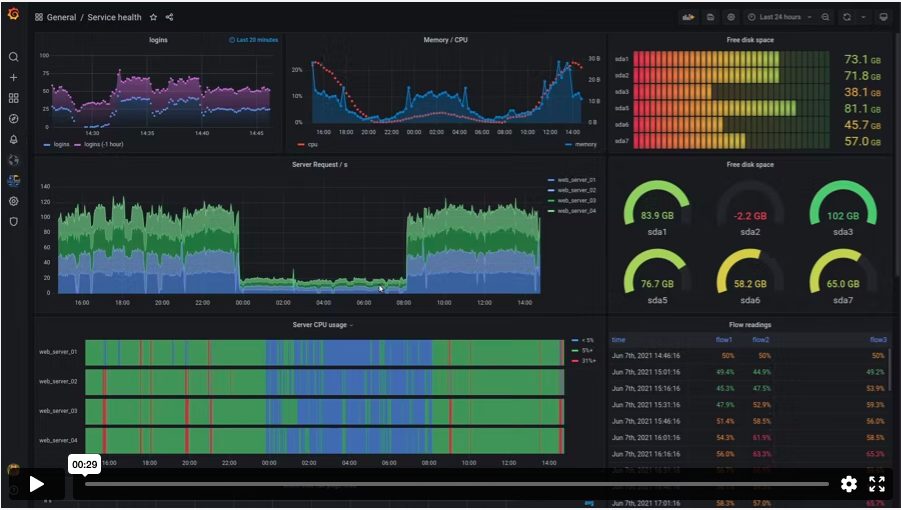
Kibanaのデモサイトがあったので、試してみます。
1. デモサイトにアクセス
2. 左上のメニューアイコンから「Visualize Library」を選択
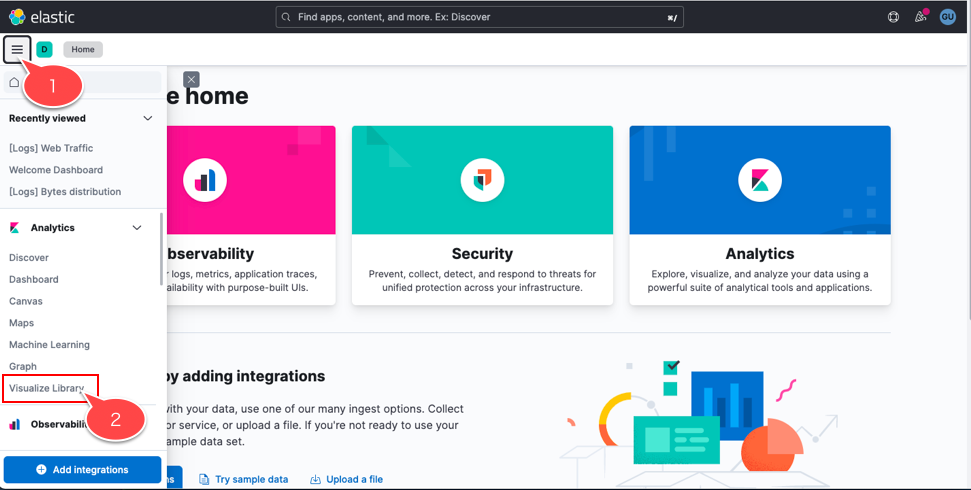
3. 画面右上の「Create visualization」をクリック
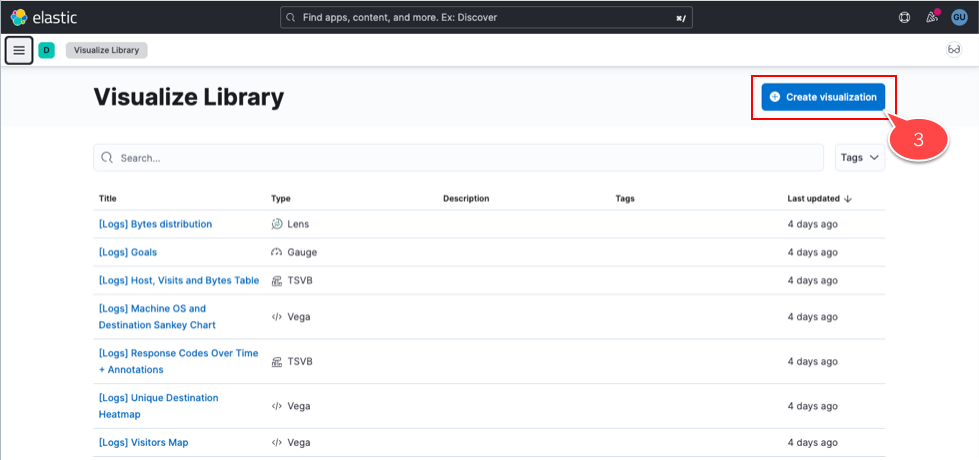
4. 作成方法の中から「Lens」を選択(ドラッグ&ドロップで可視化できると説明書きがあり、手軽そうなので)
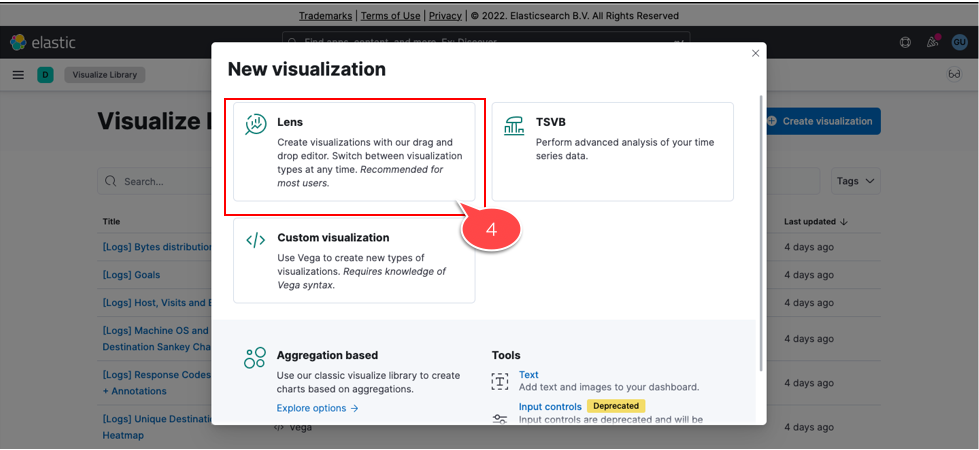
5. Lensの操作画面が表示されたら、左上の「Kibana Sample Data Logs」を確認
デフォルトは公式ページのアクセスログのようです。プルダウンで他のサンプルデータも選択可。
6. 画面左にサンプルデータの項目が並んでいるので、その中から「url.keyword」を画面中央にドラッグ&ドロップ
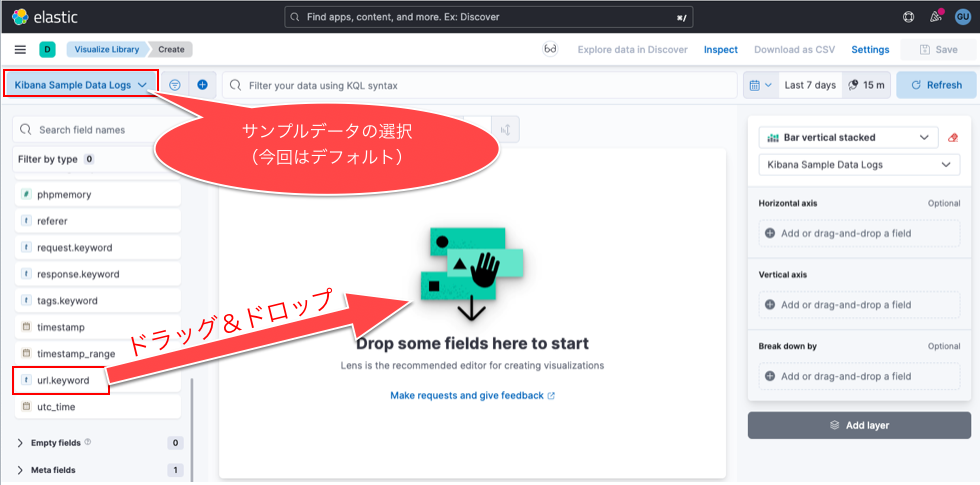
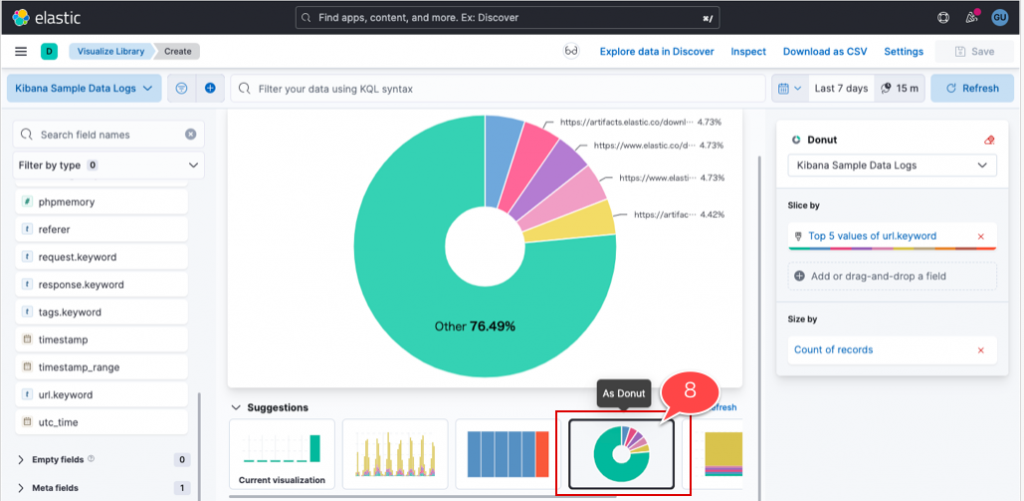
7. 画面中央にグラフが表示されるのを確認
8. 画面下部の「Suggestions」から「As Donut」を選択し、円グラフに変更
ドラッグ&ドロップだけでurlのアクセス比率のグラフができました
デモサイトでは権限がなかったので、実施しませんでしたが、ダッシュボード作成機能もあります。
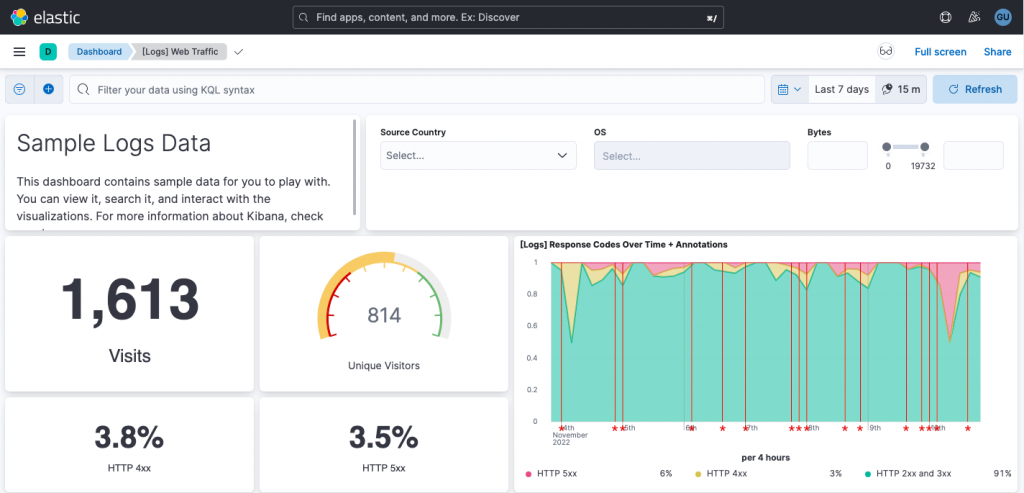
通常の可視化では、作成したグラフ組み合わせて一つのダッシュボードを作成することが多いと思います。
一画面に必要な情報が集約されていると、分析や状況把握がしやすいですからね。
デモサイトにサンプルのダッシュボードがたくさんあったので、ぜひ一度ご確認いただければと思います。
今回は無料で使える可視化ツールをご紹介しました。
最近では無料でもかなりクオリティの高いものが出てきていると思います。
今回ご紹介した以外にもたくさんツールがあるので、興味が沸いたものから、いろいろ試してみると楽しく分析できるのではないでしょうか。
GA4でページパスで計測するURLはパラメータ除外がされていない。GA4にもその設定がないため、現状ではGTMでパラメータを抜く必要がある。その前段階の処理。
function something(query) {
var ret = ”;
var pageQuery = query;
if(typeof pageQuery !== ‘undefined’ && pageQuery !== null && pageQuery !== ”){
ret = ret + “?” + pageQuery;
}
return ret;
}
コンソールでsomething(“任意の文字を入力”)し実行
今まで説明してきたGA4のデータ解析では
BigQueryをデータウェアハウスとしたアーキテクチャを構成しています。
感度の高い皆様の中には機械学習やAIのジャンルでも
BigQueryの名前が散見されていることにお気づきかも知れませんね。
AIやIOTデバイスなどは日々膨大な量のデータを発信し続けています。
今までは取得できなかった様々な有益な情報を得られる可能性があるデータ群として、
最先端のビジネスではビッグデータが活用されています。
ご存知の通り、webアクセスデータも日々膨大なデータが集約されていて、
その結果を元に近未来の予測や新規事業の創出のためにデータ活用されているでしょう。
そのような意味合いでもwebアクセス解析は
企業の有益な資産としてのビッグデータとして扱われるケースが増えています。
有効に活用していくためにもBigQureyのような
高速で高性能な分析が可能であるデータウェアハウスで扱うことが
非常に効果的になるのではないでしょうか。
今回は私が過去にデータ分析環境を旧来のRDB中心の環境から、
BigQueryをはじめとしたフルマネージドのビッグデータ解析基盤へと刷新した際のケースとともに、
BigQueryの効果について改めてご説明します。
前回お伝えしたようにRDBは複数のデータテーブルを関連付けして管理できることから、
オンラインショッピングの会員情報や社員情報に紐付く様々な情報を管理する社内システムでは
必要不可欠なデータベースになります。
しかし、ビッグデータの様にひっきりなしに膨大なデータが登録され続け、
大量のデータを抱え続けるにつれて大幅な処理速度の低下やデータストレージの逼迫が起こり
システムの最適化に要する管理コストが大幅に増えてしまいます。
また、データ分析では膨大なデータに対してSQLによる問い合わせをすることになることから、
SQLの実行から要求データの返却まで膨大な時間がかかる事があります。
ビッグデータを活用して高速な分析とともに最適な結果を求め出すことが、
変化の多い現代においてスピーディーな効果を出し、
ビジネスを実現するために要求されるため、
RDBでデータ分析環境を構築するのは限界が訪れるケースが多々あります。
そのような中でも最近ではRDBソフトウェアのアップデートによって
分析に耐えられる高性能な機能が提供されることも増えてきましたので、
RDBをアップデートしてデータ分析環境を最適化する選択肢もあるようです。
RDBで発生したデータ登録や参照に対するパフォーマンスや管理コストを解決する必要があります。
日々膨大なデータが登録され、蓄積されるデータは増え続ける中で下記の3点を中心として
システムアーキテクチャの再検討が必要になりました。
問題の解決のためにはクラウド環境でのフルマネージドシステムでのシステム設計が必要となり、
Google社のクラウドサービスプラットフォームであるGCP(Google Cloud Platform)に含まれる
BigQueryを中心としたシステム構成にすることによって、
超高速なデータ分析環境の構築が実現できました。
大量データの登録処理についての説明は割愛しますが、
GA4のデータ取り込みの際に利用したFIirebaseのような
簡単に大量のデータをBigQueryに連携できる仕組みが
GCPに含まれているサービスを活用することによって実現可能になります。
また、Amazon社のクラウドサービスプラットフォームであるAWS(Amazon Web Service)を利用して
データ分析環境を構築することも可能です。
こちらは元々Amazonのオンラインストアを支える堅牢で各種セール開催時の高負荷アクセスに対して、
柔軟にシステムの拡張ができる仕組みで利用されていた仕組みを一般に公開したサービスになります。
物理的なサーバーやネットワーク機器をそのまま仮想化したような構成で、
昔ながらエンジニアには非常にわかりやすく扱えるようになってる事が特徴です。
GCPは超高速なGoogle検索の仕組みや、Google Mapなどの膨大なデータを瞬時に捌くような
機能を中心としてシステムを構成することに特化している傾向があります。
最小構成でのシステム構成ができることから、
工夫次第ではAWSに対してより低コストでのシステム構築ができる傾向になります。
最近のクラウドサービスの円熟によって、データ分析のみならずAIや機械学習、
さらには3D CADなどのデザイン分野で高性能な処理をする事が可能となり、
AWS、GCPどちらでも高性能なシステムが運用されていて、様々なビジネスや社会基盤を支えています。
もちろんMicrosoft社のAzureも様々なケースで利用されています。
それ以外でもGCPやAWS上で動作できるデータウェアハウスの
Snowflakeや、
GUI上でのノンコーディングによるデータサイエンスプロセスの自動化が可能であるAlteryxなど
高性能かつ効果的なデータマネジメントサービスが利用されています。
個人的に興味あるのはAWSが提供しているAWS Ground Stationというサービスで、
衛星通信のコントロールやデータ処理を可能としているサービスです。
宇宙開発へどのように活用されていくかが非常に興味深いですね。
AIや機械学習を中心に発展し続けるビッグデータの活用が、
web解析シーンでも当たり前になりつつある世の中になりつつあります。
文明の夜明けから2003年までに作られた情報が
現代では2日ごとに作られている世の中になっており、
その速度は日々加速し続けています。(※)
膨大な情報を効率よく、適切に扱う事が必須になっている時代の中で、
web解析で得た情報を活用して新たなビジネスやソリューションに結び付けていくことが
非常に重要なのではないでしょうか。
私としてはAIや機械学習など比較的最近登場したテーマと同じレベルで
昔からあるWeb解析が重要視されていることは非常に喜ばしく思います。
機械学習的なアプローチでのweb解析が主流になる日も近いのではないでしょうか。
GA4のデータを日々BigQueryに蓄積するための設定方法を前回解説しました。
今回は蓄積されたデータから必要なものを集計、抽出するための方法を解説します。
データベースは検索や集計が容易できるよう整理された情報集合体です。
GA4のデータが出力されたBigQueryがデータベースになります
DBと省略する事があります。
BigQueryの他にもMySQLやPostgre SQL※など様々なデータベースがあります。
実際にデータが保存される場所はテーブルです。
DBとテーブルの関係性はSpreadSheetのファイルとタブの関係性に似ています。
※ MySQLやPostgre SQLはRDBというデータベースの種類です。
RDBはRelational Databaseの略称になり、関係型データベースという意味を示します。
特徴として複数の表でデータを管理して定義の異なる表を関係付けする事ができ、
データ処理が一貫して行うことが可能となります。
企業の社内システムやオンラインストアの会員情報管理など、
身近なところでのデータ管理に活用されています。
その一方で拡張性や処理速度に問題があり、
データ構造の変更や高速化を求めた改造などは専門的な知識を要します。
そして膨大なデータ量を扱う場合には処理速度が落ちるため、
データ分析や機械学習など大量のデータを扱う目的には向いていません。
データの操作や定義を行うために
データベースに問い合わせをするための言語です。
SQLを利用することによって、
例えば特定のデバイスからのアクセスがあったページの抽出や
特定の地域からのアクセスを抽出する事が可能になります。
その他にもSQLではデータ構造の定義変更や
データの新規登録、更新、削除をする事が可能になります。
BigQueyでは日単位で別のテーブルにデータが出力されるため、
複数のテーブルの情報を統合して結果を抽出したい場合にもSQLを使うことで実現できます。
なお、BigQueryではweb UIに直接SQL記載して実行する事ができます。
下記の画面にて、[クエリの新規追加]をクリックすると
クエリエディタが表示されてSQLを直接実行することが可能になります。
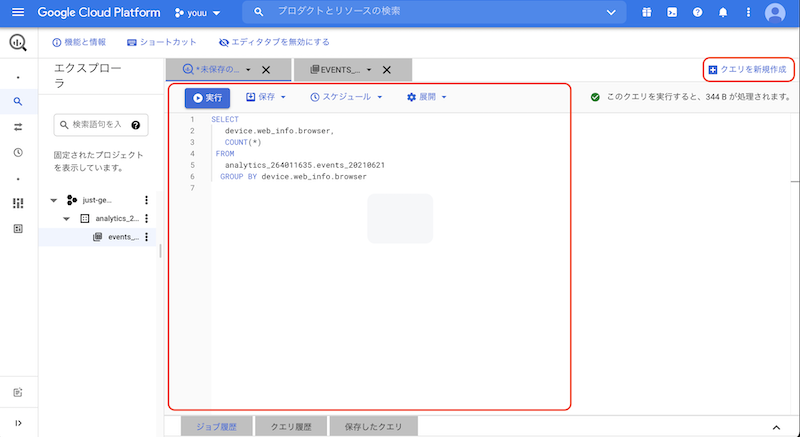
他のDBでは専用ツールの導入やPCからDBに接続するという前提が必要になりますが、
BigQueryではそのような事前準備が一切不要になります。
GA4からエクスポートされたBigQueryのデータの解析には、
データ参照命令文であるselect文のみ使用します。
それ以外の構文は使用しないのでこちらでは説明を省略します。
参照命令文を覚えるだけで十分な解析ができるため、
コツさえ理解できれば簡単に使えるようになります。
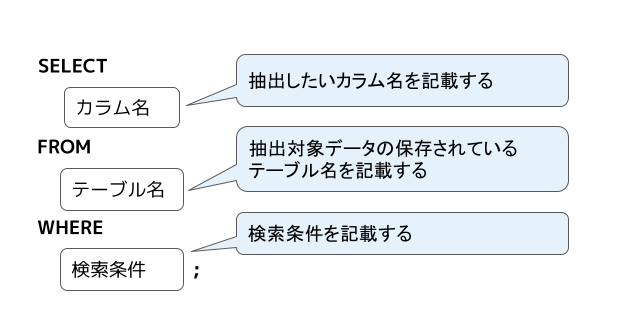
データを参照するためにSQLであるselect文は下記の構造になっています。
参照したいデータに応じて各パラメータの値を変更することで、
様々なデータの抽出ができます。
BigQueryは実行したSQLの結果サイズによって課金が発生します。
広範囲のデータを参照するSQLを実行すると大量課金に繋がるため、
参照カラムの指定、検索条件の指定を工夫する必要があります。
下記のようなSQLではデータの絞り込みがされずに
大量のデータが取得されるため避けるようにしましょう。
select *による全カラム指定でデータを取得するクエリエディタにSQLを入力すると、
下記の図のように処理されるデータサイズが表示されます。
こちらを参考にSQLを組むこともコスト削減に有効です。
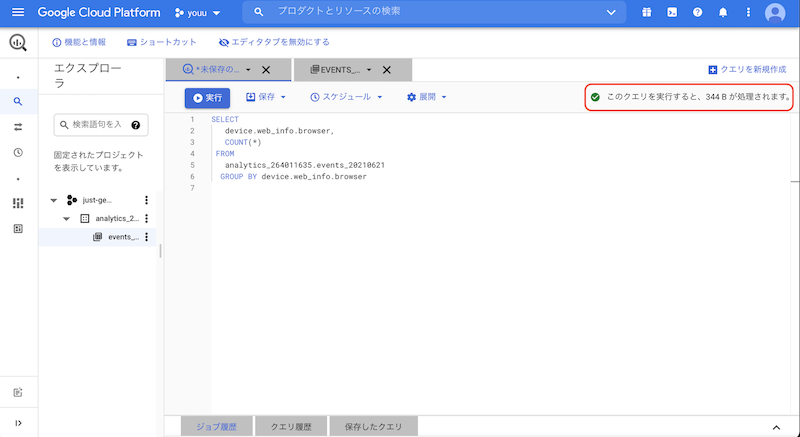
参考資料
BigQuery で費用を抑える
基本的なSQLに関数やパラメータを追加することで、
より詳細な情報を取得する事ができます。
下記のテーブルから抽出するケースを参考に、
簡単でよく使われる事例を方法を説明します。
sample_table

COUNT関数
取得するテーブルの行数を取得することができます。
SQL
SELECT
COUNT(*)
FROM
sample_table
WHERE
event_name = 'first_visit'結果
下記のようにevent_nameが first_visit のデータ集計数が取得できます。

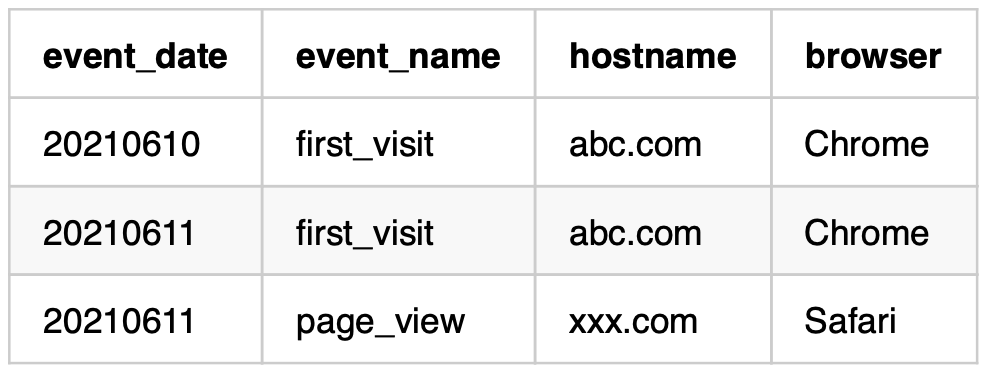
LIMIT
取得するデータの上限数を指定することができます。
SQL
SELECT
*
FROM
sample_table
LIMIT 3結果
下記のように3行分のデータのみ取得できます。
ORDER BY
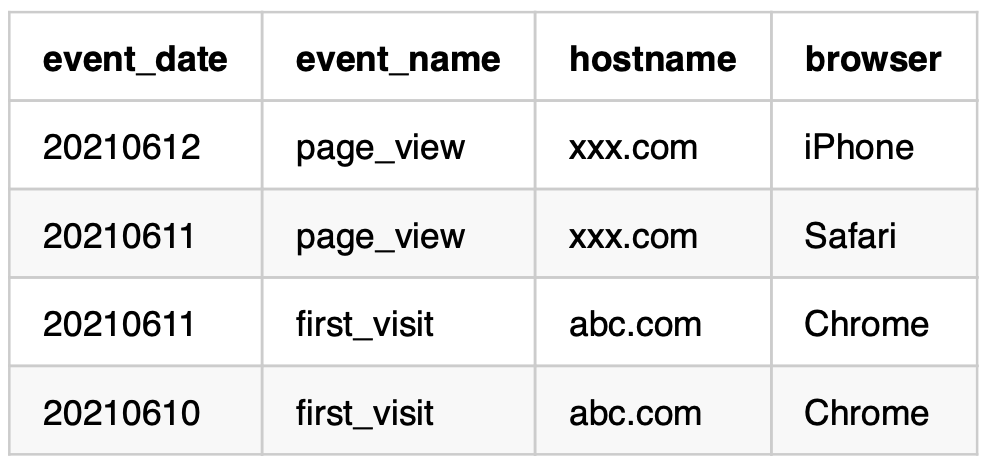
取得するデータの中でソートするカラムを指定することができます。
ORDER BYの引数によって昇順、降順を指定できます。
なお、引数を無指定の場合にはデフォルトで昇順が指定されます。
SQL
SELECT
*
FROM
sample_table
ORDER BY
event_date DESC結果
下記のようにevent_dateが降順にソートされます。
GROUP BY
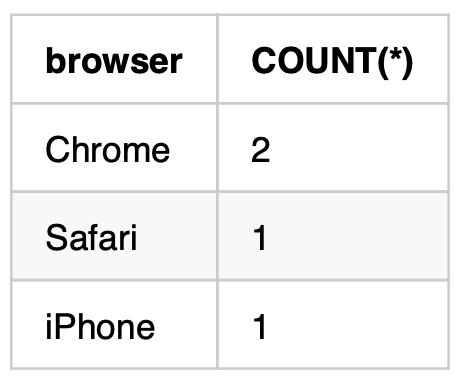
取得するデータのカラムをグループ化することができます。
COUNT関数と組み合わせてグループ毎の集計数を取得する事ができます。
SQL
SELECT
browser,
COUNT(*)
FROM
sample_table
GROUP BY browser結果
下記のようにbrowserカラムに出現するパターンが抽出されます。
COUNT関数を指定追加して、browerカラムの修正数を合わせて取得しています。
今回はBigQueryを中心としたデータベースについての基礎的な内容を説明しました。
BigQueryはWeb UI上で一連の作業が可能であり、視覚的にも非常に使いやすいです。
また、データ抽出のために別のアプリケーションのインストールや環境設定が不要です。
そしてBigQueryは大量のデータ分析をする上で最適なデータウェアハウスになりますので、 GA4との連携に非常に効果的なWebアクセス解析の実現が可能になります。
GA4のデータ分析で使用するSQLはデータ参照系の処理だけなので、
比較的簡単に覚えることができます。
事例にて説明したCOUNT関数以外にもデータ分析に役立つ関数がありますので
今後、具体的なデータ分析をするためのSQLの説明をする際に
その他の関数の使い方について説明をしていきます。
BigQueryに保存されたAnalyticsデータを柔軟に抽出して必要なデータを取得する方法として、
レコード内にネストされた情報を分解する方法を説明します。
ネストしたデータから必要なデータを抽出することで、より詳細な情報を得られるようになり、
独自のレポートを作成する際に非常に効果的になります。
前回は1つのSQLでBigQueryに保存されたデータから必要な情報を抽出する方法を説明しました。
今回は複数のSQLを組み合わせて実行した結果を用いてより詳細なデータを収集する方法を中心に説明します。
若干複雑な内容になりますが、この方法を理解する事によって、
GAの探索機能やレポートでは再現の難しい、様々なニーズに合わせたデータ分析へと近づいていきます。
BigQueryのテーブルは下記のようにレコード内にネストされた情報が多く登録されています。
前回UNNEST関数を利用してネストされたデータを取得する方法を説明しましたが、それだけでは複数のデータをネストから分解して一覧に並べることはできません。
この問題を解決するためにWITH句というSQL構文を利用して、
副問合せ(サブクエリ)を作り、名前を付与して一時テーブルとして扱うことができます。
主にGA4データのBigQuery分析においては下記の2点のために利用します。
まずは基本的なWith句の使い方を説明します。
BigQueryでは1レコードにpage_titleとpage_locationがまとまっていて、
それぞれの組み合わせで何軒ずつのレコードが登録されているかがわかりにくい状態です。

下記のSQLを実行することでpage_titleとpage_locationの
組み合わせのレコード件数を集計することが可能になります。
-- WITHを定義してt1という一時テーブルに情報を取集する
WITH t1 AS (
SELECT
-- event_paramsにネストされたデータからkeyがpage_titleの値をtitleという項目名で取得する
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = "page_title") AS title,
-- event_paramsにネストされたデータからkeyがpage_locationの値をlocationという項目名で取得する
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = "page_location") AS location,
event_name
FROM
`analytics_264011635.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20211101'
AND '20211110'
)
SELECT
title, -- t1で取得したtitle
location, -- t1で取得したlocation
COUNT(*) as count -- レコード件数
FROM
t1
WHERE
event_name = "first_visit" -- event_nameがfirst_visitの値を抽出
GROUP BY location, title -- SELECT句に列挙したカラム名をグループ化する
with句を日単位のセッション数を取得する方法を説明します。
データを取得する上で視認性を向上させるためにevent_timestampのフォーマットをYYYY-MM-DD型に変換します。
ユーザー(ブラウザ)特定IDであるuser_pseudo_idとevent_paramsに含まれているga_sessionを結合した値を1セッションとして扱います。
上記の情報から1日あたりのセッション数を集計することが可能になります。
WITH
t1 AS (
SELECT
DATE(TIMESTAMP_MICROS(event_timestamp), 'Asia/Tokyo') AS target_date,
CONCAT(user_pseudo_id, CAST((SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') as STRING)) AS sid,
FROM
`analytics_264011635.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20211201'
AND '20211210'
AND event_name = 'session_start' )
SELECT
target_date,
COUNT(DISTINCT sid) AS sessions
FROM t1
GROUP BY 1,
ORDER BY 1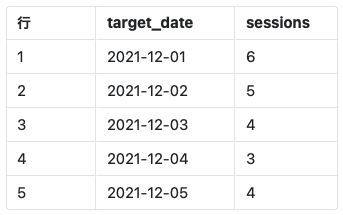
with句を利用してページ別ランディング数・離脱数・直帰数を取得して、離脱率を計算した結果を一覧化する方法を説明します。
このケースではWITH句による一時テーブルを2つ生成します。
一つ目の一時テーブル(t1)ではevent_paramsにネストされたpage_locationのデータと、それに紐付くセッションIDを取得します。セッションIDの形式は前項で説明した内容と同じものになります。
二つ目の一時テーブル(t2)ではt1で取得したデータに対してSQLを実行してアクセスデータを収集します。
最終的にt2の結果に対してSQLを実行して一覧を出力します。
WITH
t1 AS (
SELECT
event_timestamp,
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location') AS page_location,
CONCAT(user_pseudo_id, CAST((SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') as STRING)) AS sid
FROM
`analytics_264011635.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20211001' and '20211031'
AND event_name = 'page_view'
)
,t2 AS (
SELECT
page_location,
CASE
WHEN ROW_NUMBER() OVER(PARTITION BY sid ORDER BY event_timestamp) = 1 THEN 1
ELSE 0
END AS entry,
CASE
WHEN ROW_NUMBER() OVER(PARTITION BY sid ORDER BY event_timestamp DESC) = 1 THEN 1
ELSE 0
END AS exit,
CASE
WHEN COUNT(1) OVER(PARTITION BY sid) = 1 THEN 1
ELSE 0
END AS bounce
FROM
t1
)
SELECT
t2.page_location AS page_location,
SUM(t2.entry) AS entry,
SUM(t2.exit) AS exit,
SUM(t2.bounce) AS bounce,
IFNULL(SAFE_DIVIDE(CAST(SUM(t2.entry) AS numeric), CAST(SUM(t2.exit) AS numeric)), 0) AS exit_ratio
FROM t2
GROUP BY 1
ORDER BY 2 DESC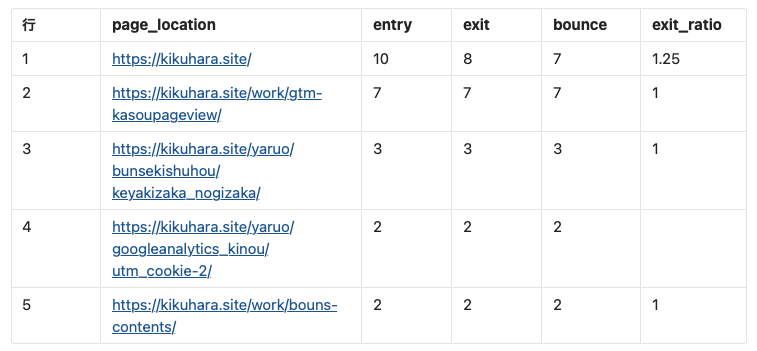
複数のSQLを組み合わせてより詳細なレポートを出力する方法について説明しました。
取得したいデータを1回のSQLで取得できない場合はWITH句を利用して一時テーブルを作成することで、データを階層的に収集して使いやすい形にフィルタリングすることが有効になります。
特にBigQueryに登録されるデータの活用はネストされているデータをうまく取り扱うことがコツになります。
前回説明したUNNEST関数とWITHを組み合わせて用途に応じたSQLを生成することが、さらなるデータ活用やニーズに応じたレポートを柔軟に生成するために重要になります。
GA4からBigQueryに保存されたAnalyticsデータを利用しSQLで分析をする方法を説明をします。
BigQueryを利用する事で、必要に応じたデータを自由に取得することができます。
GA4の標準レポートや探索レポート(カスタムレポート)では出ないレポートが必要な際に役立ちます。
日々のアクセスデータをBigQueryに保存し続けていても、
どのように活用していくのかが難しいと思います。
Google Analyticsの画面から参照できるデータと同じような結果を
BigQueryから取得する方法を説明します。
※ 逆にいうと、GA4の管理画面、探索機能やレポートで
再現できないデータ分析がBigQueryでは可能となります。
理由としては、最小単位でのローデータをBigQueryで持ってるためです。
GoogleAnalyticsを利用して下記のようなデータを画面がら簡単に参照することができます。
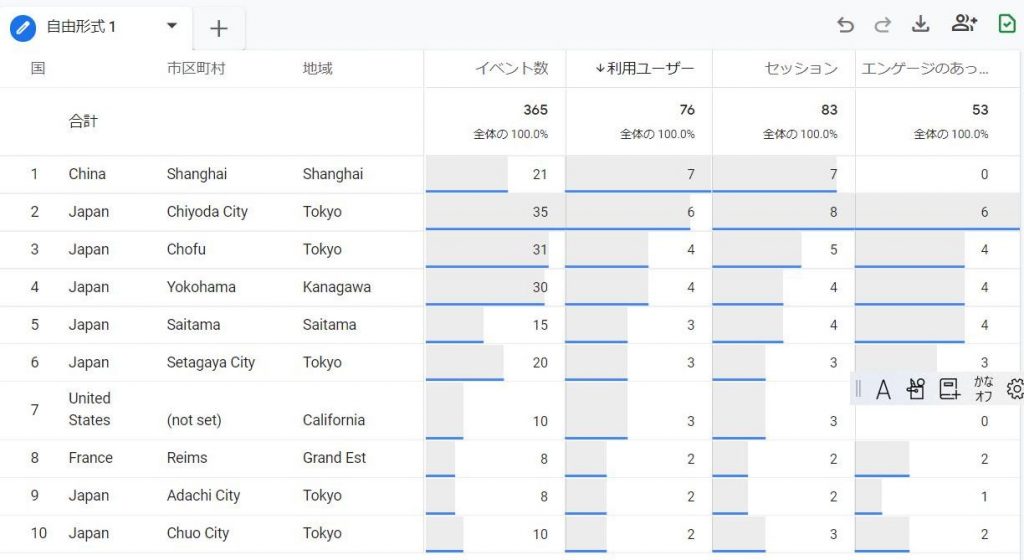
Big Queryを利用して下記のようなデータを画面から簡単に参照することができます。
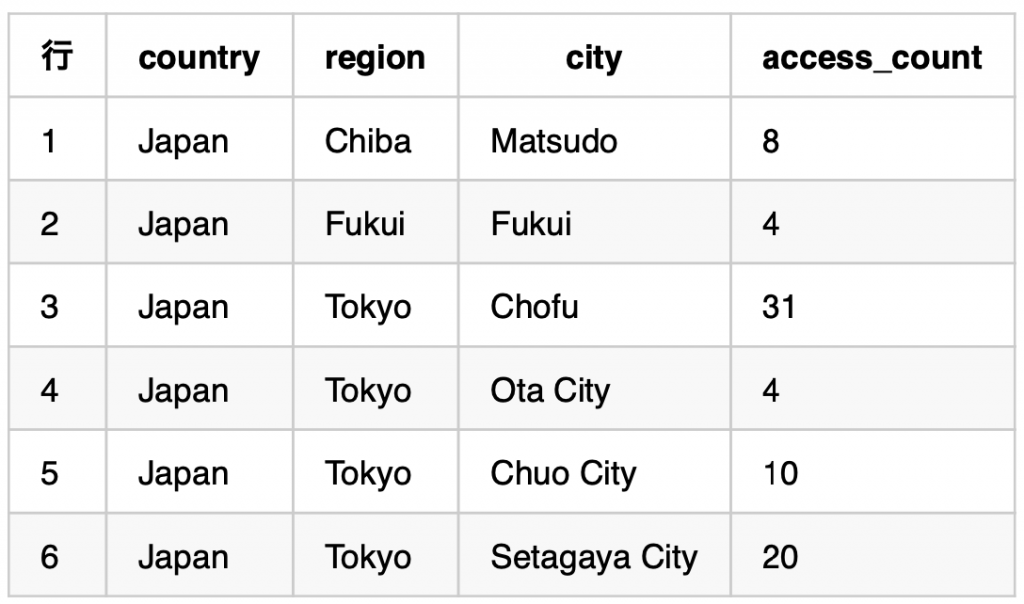
SELECT
geo.country,
geo.region,
geo.city,
count(*) AS access_count
FROM
`just-genius-216220.analytics_264011635.events_202107*`
GROUP BY
geo.country, geo.region, geo.citySQLによってデータの抽出・集計をする事ができるので
数種類のデータ抽出のアイディアを説明します。
上述のSQLを下記のように修正します。
並べ替え対象にしたいカラムに下記の引数を指定して利用します。
SELECT
geo.country,
geo.region,
count(*) AS access_count
FROM
`just-genius-216220.analytics_264011635.events_202107*`
GROUP BY
geo.country, geo.region
ORDER BY
access_count DESC
このように都道府県毎のアクセス数を一覧化して降順で並び替る事ができます。
サイトの流入経路毎のアクセス数を取得する場合は少し工夫が必要になります。
流入経路は下記のようにネストされた項目に保存されいてるので、
ネストを分解してデータを取得する必要があります。

SELECT
param.value.string_value AS page_referrer,
count(*) AS access_count
FROM
`just-genius-216220.analytics_264011635.events_202107*`,
UNNEST(event_params) as param
WHERE
param.key = "page_referrer"
GROUP BY
param.value.string_value
ORDER BY
access_count DESCネストされた項目の値を取得する際にはUNNEST関数を利用して
ネストされている項目名を指定することによって分解された結果を取得する事ができます。
下記のようにネストされたカラムのトップにあたるevent_paramをUNNEST関数に指定します。
UNNEST(event_params) as paramこれによりparamという名称でデータを参照することが可能になります。

特定月のデータを抽出するだけではなく、開始終了日を指定したデータ抽出をする事ができます。
日単位のページビューを一覧化するSQLを参考にすると下記のようになります。
SELECT
DATE(timestamp_micros(event_timestamp), 'Asia/Tokyo') AS target_date,
COUNT(1) AS page_views
FROM
`just-genius-216220.analytics_264011635.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20210715' AND '20210815' AND
event_name = 'page_view'
GROUP BY 1
ORDER BY 1_TABLE_SUFFIXを利用して対象テーブル指定することができます。
FROM句のテーブル名末尾の日付部分を*(アスタリスク)にすることによって、
WHERE句でBETWEEN句を利用して抽出することが可能です。
GROUP BY, ORDER BY による集計、並び替えカラムは明示的にカラム名を指定する以外に、SELECT句の表示順を指定することも可能です。
上記の例では1行目に指定したtarget_dateをキーに指定しています。
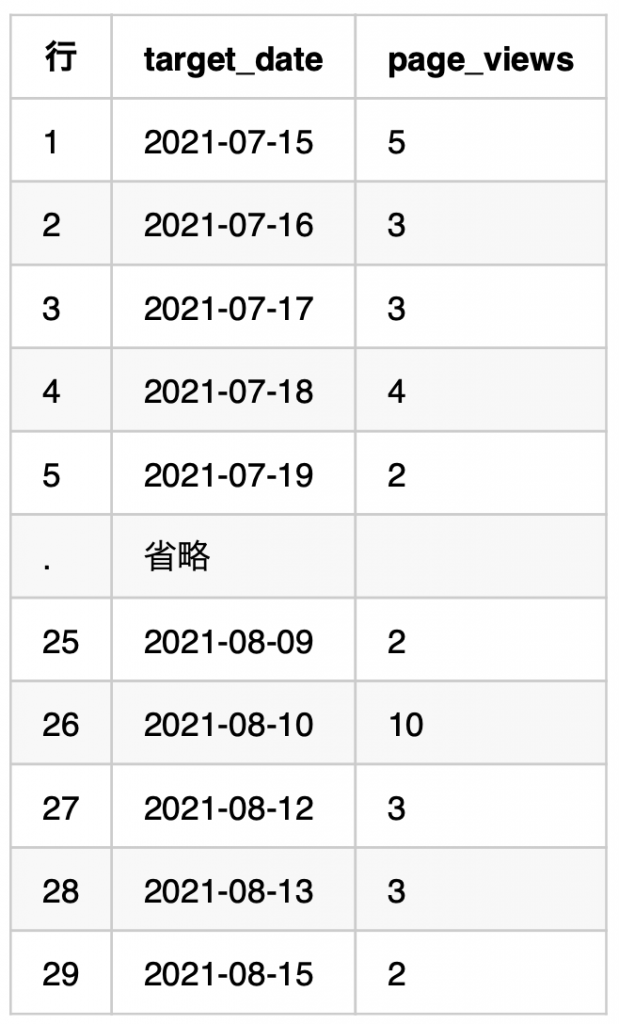
今回説明したようなシンプルなSQLによってBig Queryからデータを抽出することができます。
応用的な使い方として用途に合わせた関数を利用して
下記のような抽出をするSQLを説明していく予定です。
基本的なSQLの使い方を覚えながら、
用途に応じたSQLを組み立てていき必要に応じて関数を利用するような流れで
少しずつSQLに触れる機会を設けていくことが
要求に基づいた効果的なデータ解析を実現していくための道筋になると思います。
GA4(googleアナリティクス4)のデータを有効に活用するためにGoogleBigQueryと連携して自動的にデータを収集する設定、テータの構造について、GCP導入・移行実績の豊富なエンジニアが説明します。
Google Analytics 4 properties(GA4)は
モバイルアプリ向けの解析ツールであるGoogle Anaytics For Firebaseをベースとして
再設計された新世代のGoogle Analyticsになります
GA4を利用することで新たに実現可能になる要素として下記の内容が挙げられます
・ Googleが提供してる機械学習を活用した顧客行動分析
・クロスプラットフォーム広告との統合
・日々最適化され続けるコンプライアンスやプライバシー規定に配慮したデータ活用
時代の変化が加速を続け、扱えるデータが日々増大していく中で、
Googleの持つ最先端の機械学習やデータ分析モデルを利用してアクセス解析することにより 効果的なデータ活用が可能となります
GA4のROWデータをBigQueryにエクスポートしてデータ分析をする事によって、 大量のデータを柔軟に分析することが可能となります
一度設定をする事により、毎日更新されたデータがBigQueryに自動的にエクスポートされるので 分析をする際にGA4からデータを取得する必要はなく、BigQueryを参照するだけでデータ分析が可能になります。
BigQueryはGoogleが提供するクラウドサービスであるGoogle Cloud Platform(GCP)というに含まれるデータウェアハウスサービスです。
大量のデータを高速で扱う事ができるため、円滑なデータ分析が可能となります
最近では機械学習モデルやAI開発におけるデータマネジメントにも活用されています
データエクスポートをするためにはFirebaseでの設定が必要になりますので次項 で説明します
firebaseの設定により、bigqueryに対して自動的にデータエクスポートをする設定について説明します
前提としてGCPが利用できる状態にする必要があります

firebaseプロジェクトをBigQueryにリンク付け
[プロジェクトの概要]の横にある歯車マークをから[プロジェクトを設定]を選択します
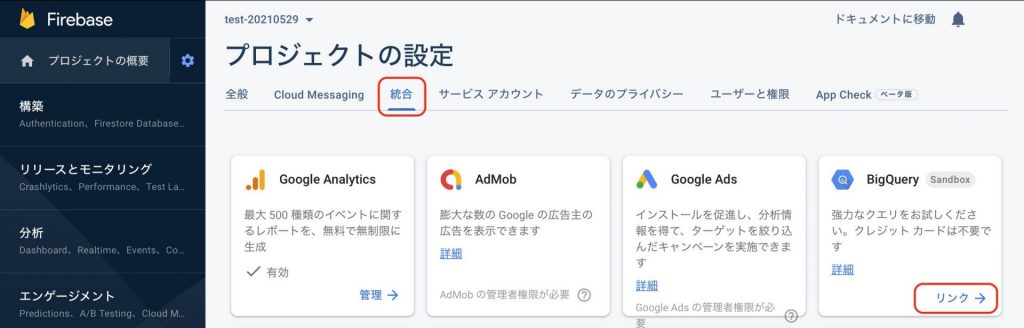
[プロジェクトの設定]画面に遷移するので、[統合]を選択してBigQueryのカード内に表示される[リンク]を選択します
[FirebaseとBigQueryのリンクについて]に遷移するので、ページ下部にスクロールして[次へ]を選択します
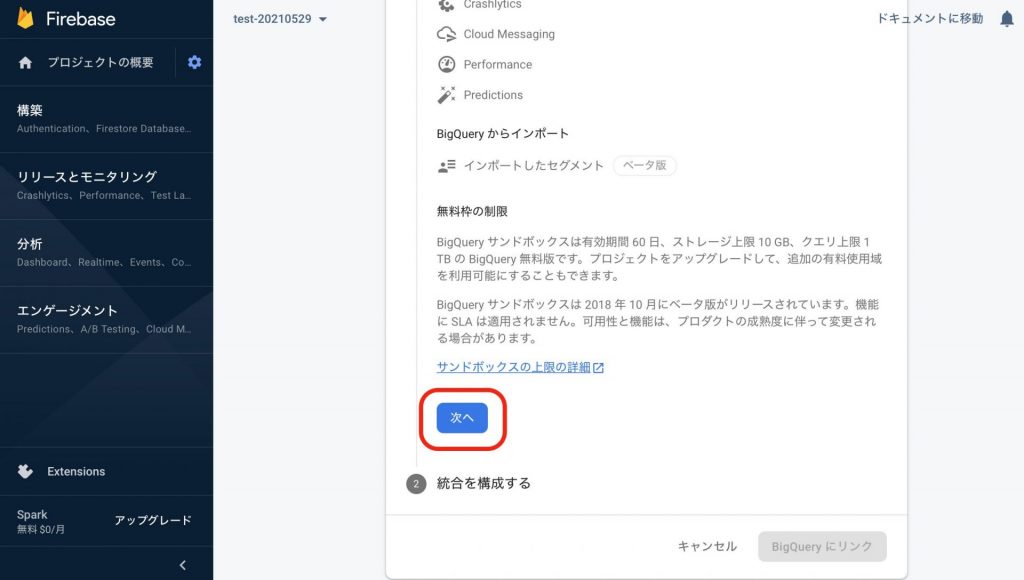
次画面の最下部にある[BigQueryにリンク]を選択します
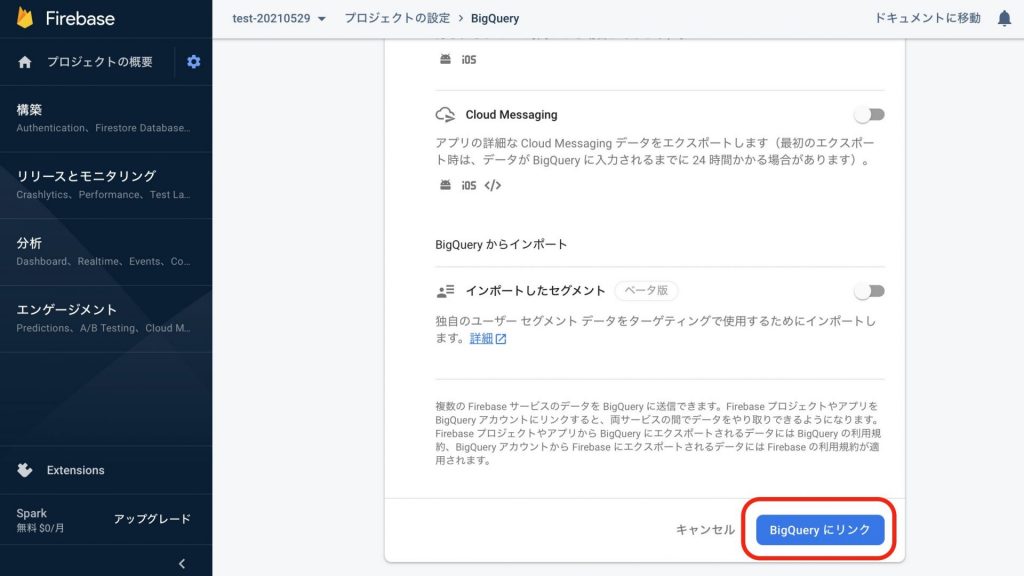
[統合を構成する]画面に遷移するので、下記の項目を選択します
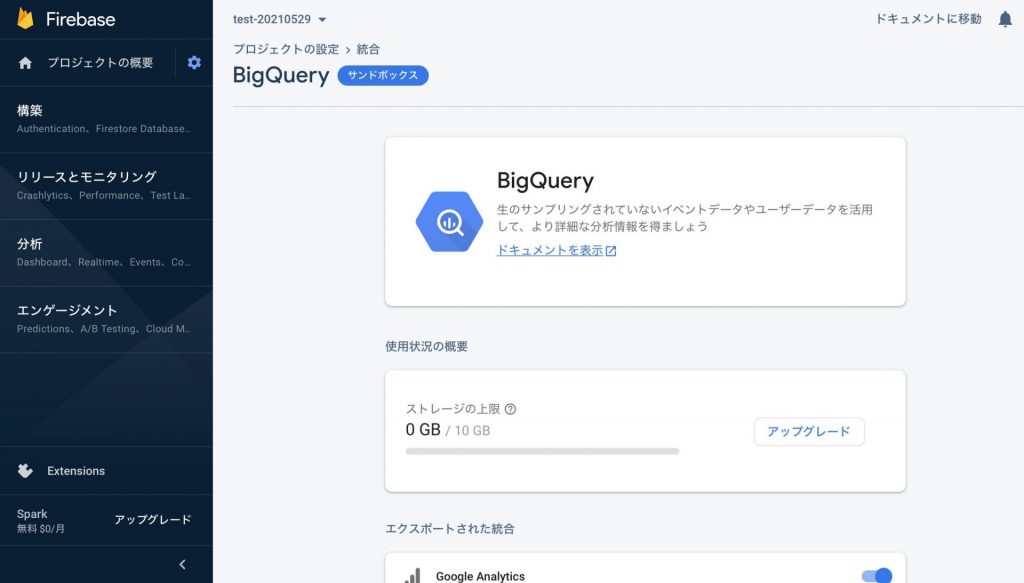
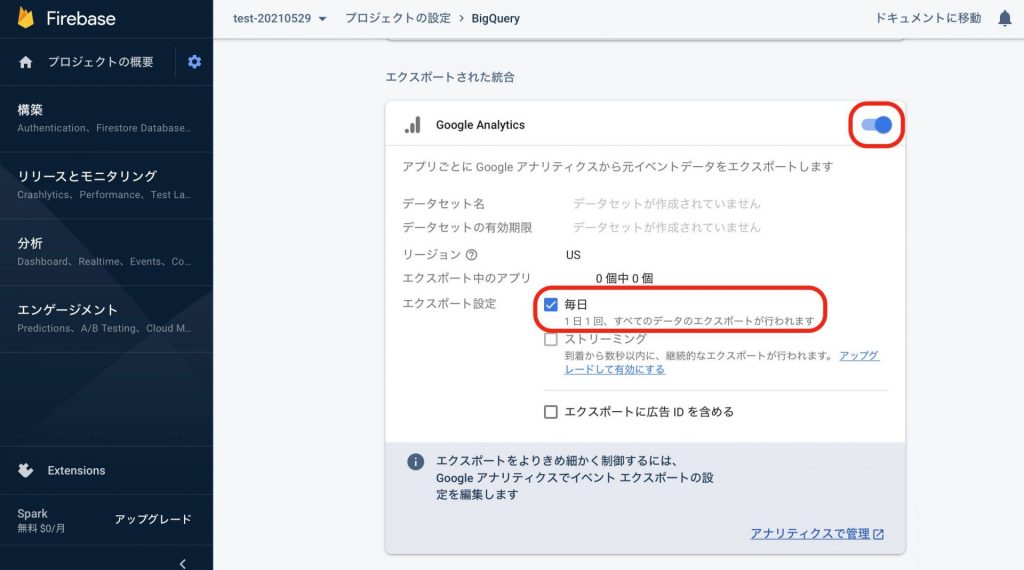
設定完了後、24時間以内にBigQueryにGAのデータエクスポートが開始されます 今後は毎日自動的にデータエクスポートが実行されます
firebaseでエクスポート設定したプロジェクト名のデータセットが生成され、その配下に日付ごとにテーブルがエクスポートされます
なお、下記に定義している値の[yyyymmdd]にはエクスポート日付が登録されます
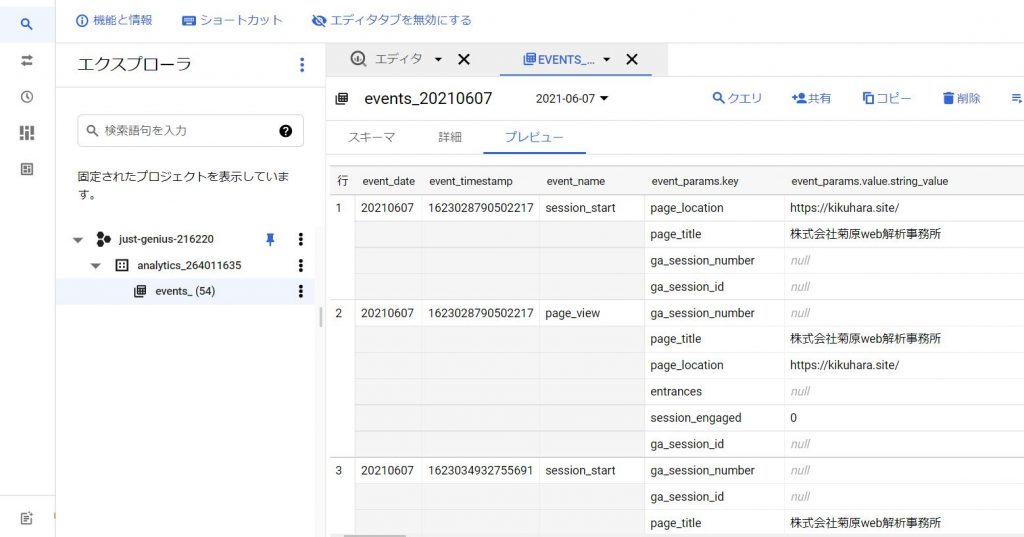
events_interday_yyyymmdd
events_yyyymmdd
BigQueryにエクスポートされるスキーマの中で、代表的な値を抜粋して説明します。また、 エクスポートされる全スキーマ仕様の詳細は下記になります。従来のgoogleアナリティクスとは計測の仕組が根本から異なるので、基本的なフィールド名の把握は必須と言えるでしょう。
https://support.google.com/analytics/answer/7029846?hl=ja
| フィールド名 | データ型 | 説明 | 登録されるデータの例 |
| event_date | STRING | イベント発生日 | yyyymmddフォーマットの日付 |
| event_name | STRING | イベント名 | firstvisit(初回)訪問, pageview(ページビュー) … |
| user_id | STRING | ユーザー識別子 | APIによって設定されるユーザー固有のID |
| device | RECORD | デバイス情報 | IPhone(アイフォン), Chrome(クローム) … |
| geo.contient | RECORD | 端末、ブラウザID | Asia |
| geo.country | RECORD | 大陸 | Japan |
| geo.region | RECORD | 都市 | Tokyo, Osaka … |
BtoBはトラフィックの質が重要
どのサイトでも質は大事だが、BtoBはBtoCと比べより顕著だろう。なぜなら、基幹システムの導入など一定規模の予算を必要とする企業は限られており、その他の予算がない企業が問合せをしてきても無駄な労力を使うだけだからだ。BtoBは一定以上の金を持っている企業以外を求めていない。これはBtoCでは想定しない事といえる。
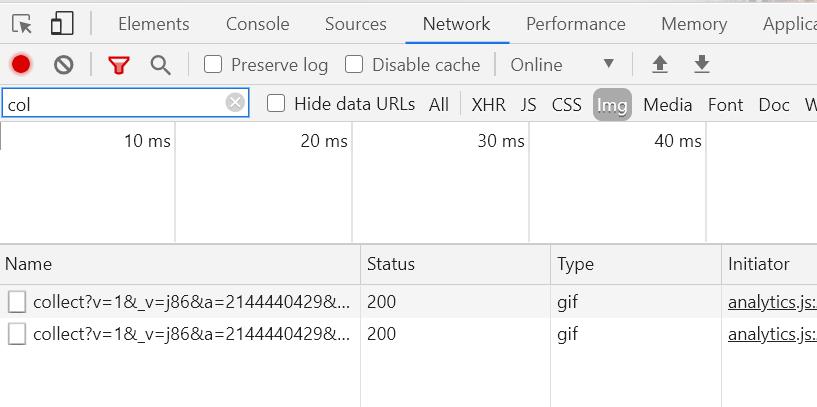
クロムの検証モードでネットワークを選択。
collect~~のimgタグでstatusが200なら送信出来ている証明となる。
上記図では1つのGTMからUAの異なるGAタグを2つ発火させているため、2つのイメージタグがGAサーバに送信されていることとなる。該当箇所をクリックし詳細を見るとUAの番号などGAで利用しているデータが見て取れる。
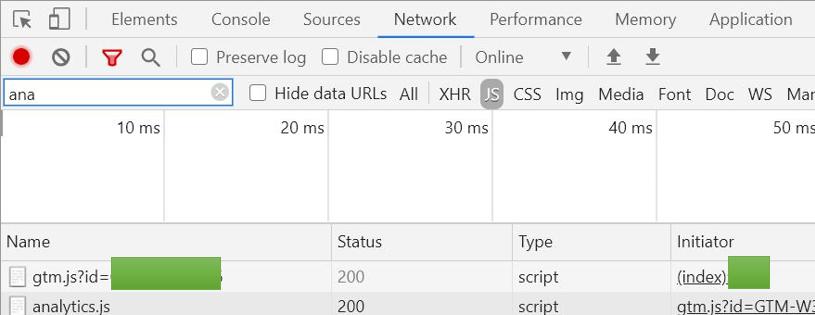
同じくクロムブラウザのネットワークを見る。ここもstatusを見ればOK
流れは次の通り。サイト訪問→ページ読み込み→GTMタグ読み込み→GTM内のGAタグ読み込み→タグ内のIMGタグをgoogleのサーバに送信
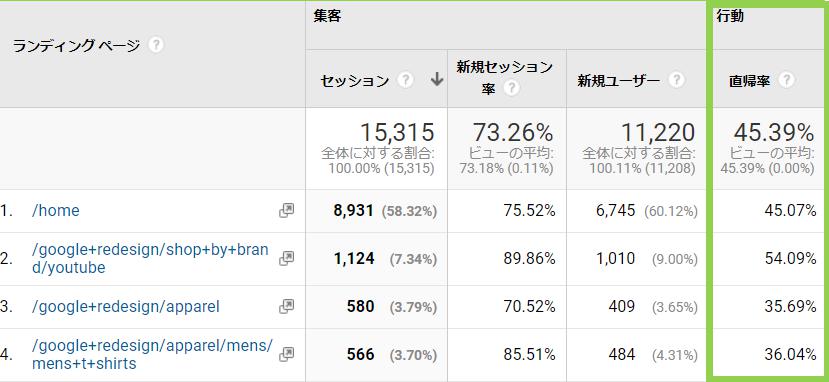
アクセスの多いページや新しく作成したページの評価をするときに、Googleアナリティクスのどんな指標を使っていますか?
多くのかたは直帰率や離脱率、次いでページ平均滞在時間を利用しているのではないでしょうか。
もちろんこの指標だけでも数値の比較を行いページ改善を行うこともできます。
しかし指標の意味をきちんと理解した上で利用をしないと、誤った理解と施策に繋がってしまう事があります。
今回は直帰率の正解な理解と正しい利用方法、そしてより正解にユーザ行動を把握するための指標と使い方について記していきます。
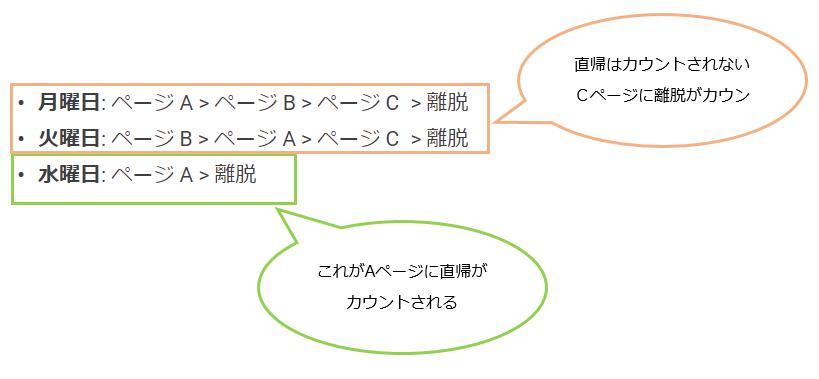
まず直帰率はサイトに訪問したページ(入り口ページやランディングページと呼びます)だけを見て、離脱したセッションの割合を指します。
言い換えると1ページだけを見て去ってしまった人がどれくれいか、という事になります。
基本的にはサイトに訪問してくれて、1ページだけを見るよりもたくさん見てもらう方が良いので、直帰率が高いとなるとページを改善しましょうという流れになるのです。
ただここで注意が必要です。
それは検索エンジンが進化しているという点です。
10年~15年前の昔の検索エンジンは、どんなキーワードを打っても、そのサイトのTOPページが上位に表示される可能性が高かったです。
まだ検索エンジンが賢くなかったからでしょう。
しかし今の検索エンジンはユーザが打つキーワードにとってより関連性・親和性の高いページを上位に表示します。
ユーザにとっては少ないクリックで目的の情報にたどり着けるわけであって、これは検索エンジンの狙いでもあります。
このような検索エンジン側の進化を背景に直帰率を考えるといかがでしょうか?
ユーザは詳細なキーワードを打ち、目的の詳細ページに入口ページとして訪れ、情報を取得し満足し離脱をする これは直帰です。
はたまた、詳細なキーワードを打ち、詳細ページに来たが、情報がなかったりわかりにくかったりで直帰をした。 これも直帰です。
どうでしょうか。ユーザの満足度は全く違うのに、いずれも直帰としてカウントされてしまいます。
ここまで理解が進んでくると、直帰率だけでのコンテンツ改善だと厳しいと思われるのではないでしょうか。

スクロールの計測はgoogleアナリティクスのイベントトラッキングの機能を利用します。イベントという概念はページ(URL)の遷移がない状態でのページ上での行動を計測するときに有効です。
グーグルアナリティクスのイベントトラッキングの例を上げます。
ECサイトのカート追加ボタンや、スマホ時の電話タップボタン、外部サイトへのタップ計測やSNSシェアボタンなど、様々な計測が可能です。ただそのサイトにおいて価値の低い動作においては実装・計測を行う必要はありません。大事なことは課題を解決するためのどの指標をKPIとして、そのKPIを改善するためにデータ蓄積、分析、改善を行い成果を上げる事です。
スクロール設計の場合は、その名のとおりどこまでスクロールをしたかといった行動を率で計測することが、可能です。
なので、50%の半分まで見てくれた!とか、80%の記事の部分は全部みてくれた!といった評価が可能です。コンテンツの重要度がます昨今、必要なkpiになることは間違いありません。
一方タイマー設計は、ページが表示されてから(読み込まれてから)指定した秒数でイベントを計測することが可能です。
ページに滞在している時間が長いほど文字を読んでくれていルという定義であればこちらも必要なkpiとなります。ちなみにですが、googleアナリティクスにはデフォルトの指標でページ滞在の精度は低いです。なぜならページ遷移間の秒数を計測しているためです。
つまり直帰と離脱ページは滞在時間のカウントがされないということです。
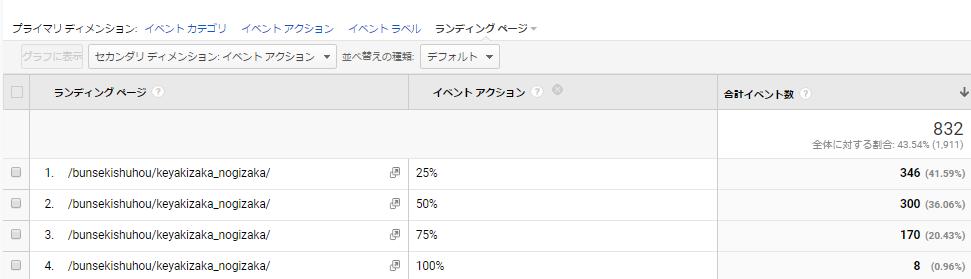
もう1歩進んだ使い方もご紹介します。
スクロールの実装と計測を行い、どこまで記事を読んでくれているかの確認は出来ました。ただ記事を読んでくれたユーザが、その後CVをしてくれたかが最も重要です。(メディアサイトの場合を除く)
要は、コンテンツマーケティングを行う目的はそのサイトの成果(コンバージョン)を増加させるためです。ですので、記事を読んでくれたとしてもコンバージョンに貢献しているか、寄与しているかという視点が重要です。
グーグルアナリティクスやグーグルタグマネージャーで設定面の記事はそれなりに見受けられますが、データの活用面における記事は少ないと感じてましたので、書いてしまおうと思います。
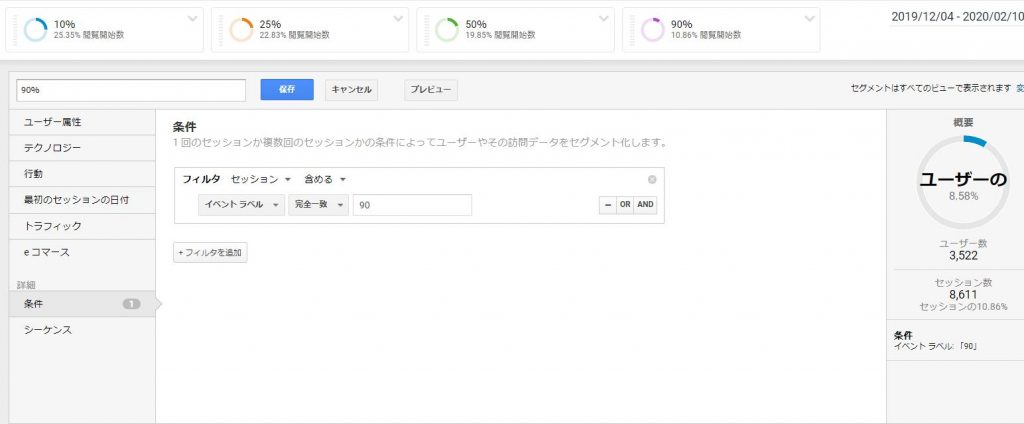
計測したスクロール率をセグメントで設定します。
そうすることで、ユーザ行動(セッションやユーザ)とデータが紐付き、スクロール率とCV/CVRの相関が追えます。
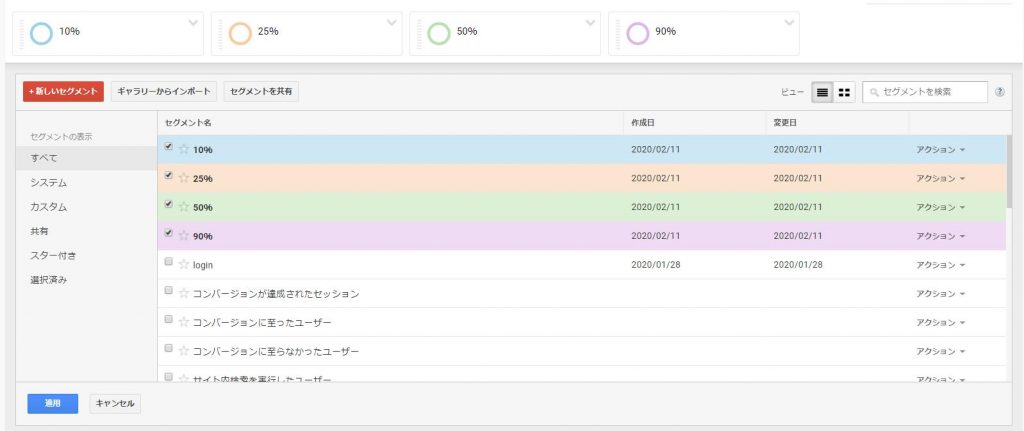
データ分析の基本はセグメントと比較です。今回の場合だとスクロールのセグメントを4つ作成します。そしてレポートに反映すると次のようになります。
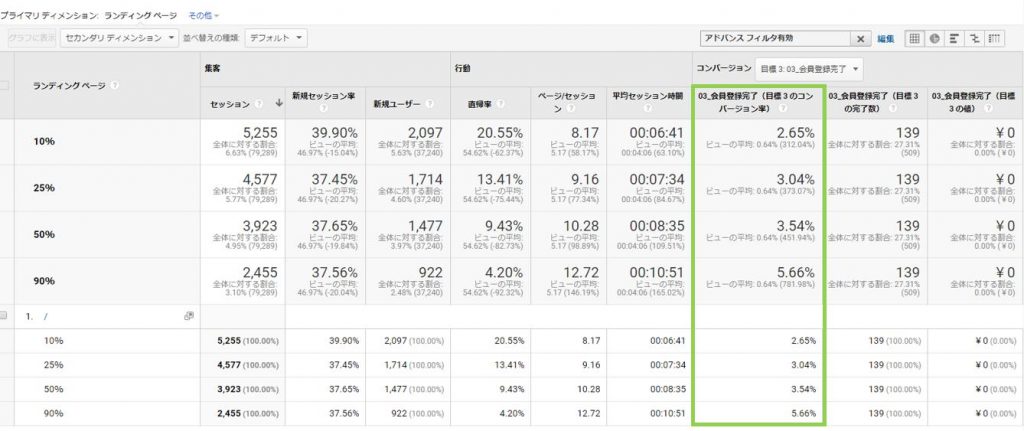
トップページのスクロール状況だけでなく、どこまでスクロールしたユーザがコンバージョンが多いかがわかります。このデータでは90%以上スクロールした時のCVRが最も高いことがわかました。このようなユーザデータが取れてくるとどの箇所から改善を進めていくべきかというヒントが多く生まれます。
今思いつきで書いただけのものも記しておきます。
このようにページの改善を行うためには、今そのコンテンツがどれくらい利用されているか、どの部分(訴求)がユーザに効果を与えいるかがわかります。
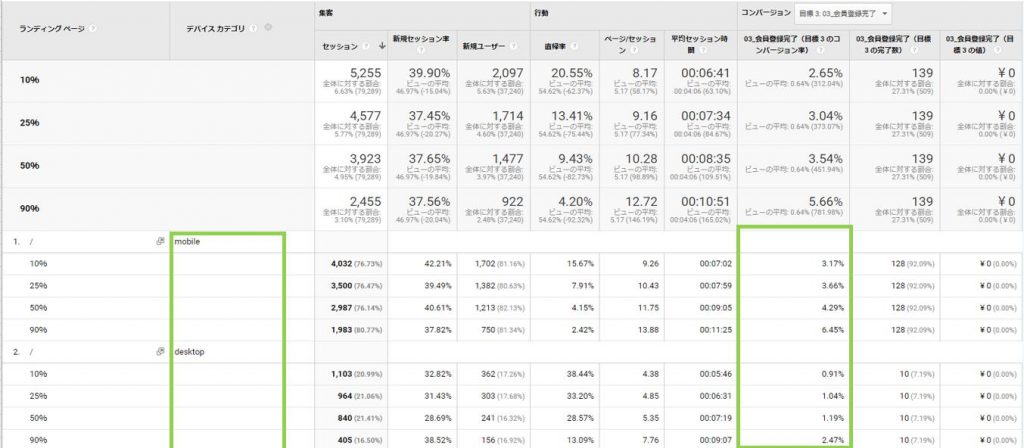
条件:ユニーク化したいページのタイトルタグが固有であること。
※詳細に言うとタイトルタグでなくとも、固有のH1タグでもcssでも何でも良い。
ページ単位で固有のものがなければデータレイヤーを使ってtrackページビューを指定するしかない。
メリット:1つのルックアップテーブルで複数の仮想ページビュー作成が可能。
デメリット:パラメータが付与されているURLのパラメ以降がGAレポートでカットされてしまう。GAパラメじゃなくサイト構造で作られているURLね。
トリガーで指定したタイトルの場合、
そのタイトルタグをpageのフィールドにセットする。みたいな事で実現可能。
メリット:方法①のように対象ページ以外のURLが変に修正されてGAに反映されることはない。
デメリット:1つの仮想ページビューを作成する時、GAタグをGTM内で1つ作成する必要がある。ルックアップテーブルのように纏めては出来ない。
両方とも実際に試してみたが、今回の案件では仮想ページビューは2つしか設定しなかったので、 ②を選択した。
カスタマイズやコードを書いたりすれば①でも仮想化以外のページもコントロールできるかもしれないねー
最新記事

サウナダッシュボード 2025/11/19
日本のサウナ情報を網羅するダッシュボード公開 2024/11/20
無料で使えるBI(可視化)ツールのご紹介 2022/11/25
GTMでpageQery変数の頭に?マークをつけるカスタムjavascript 2022/05/24

GCPエンジニアが語るBigQueryを使うメリット 2021/12/18
月曜〜金曜 am11〜pm18




